Point-SAM: Promptable 3D Segmentation Model for Point Clouds
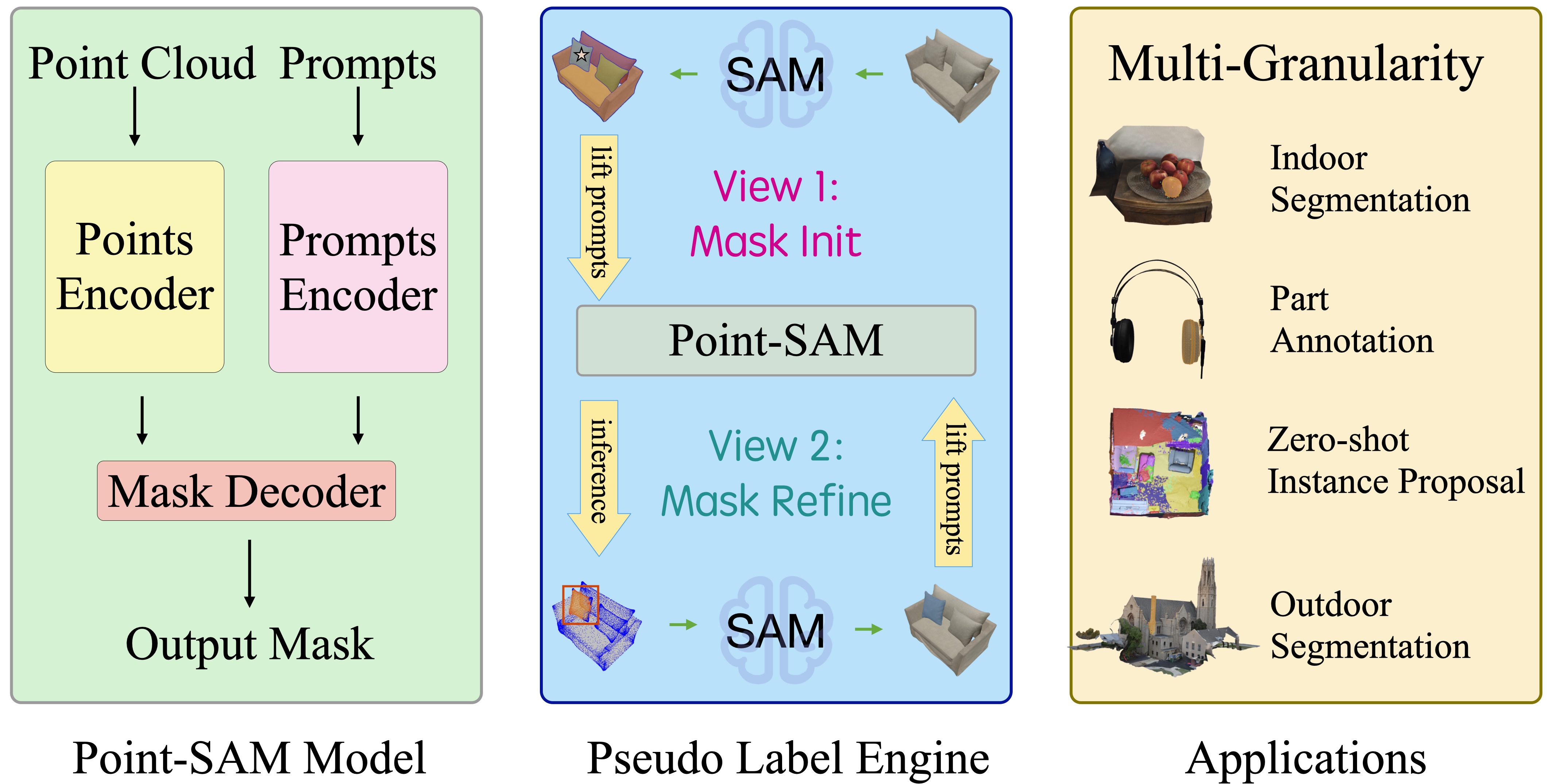
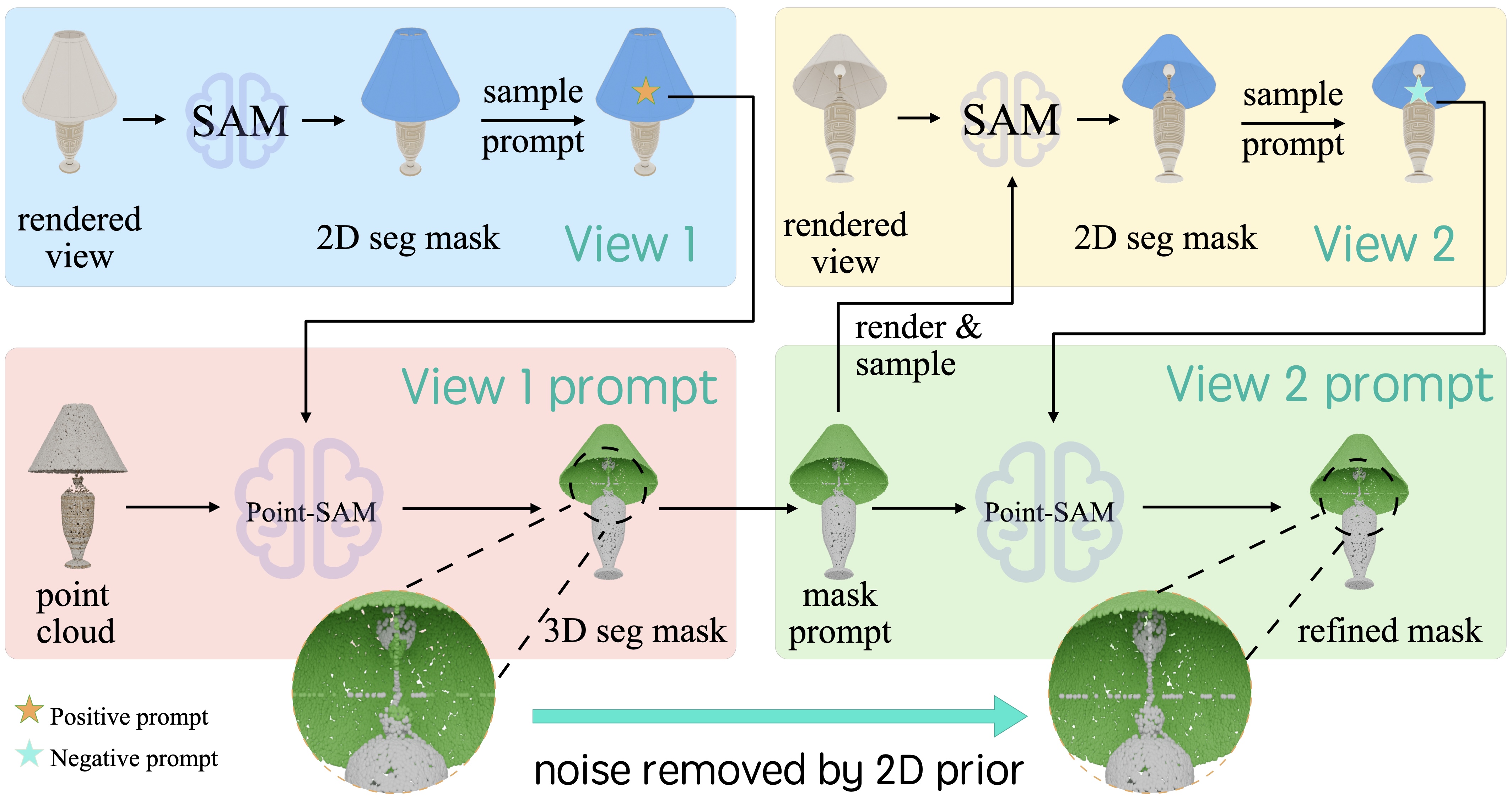
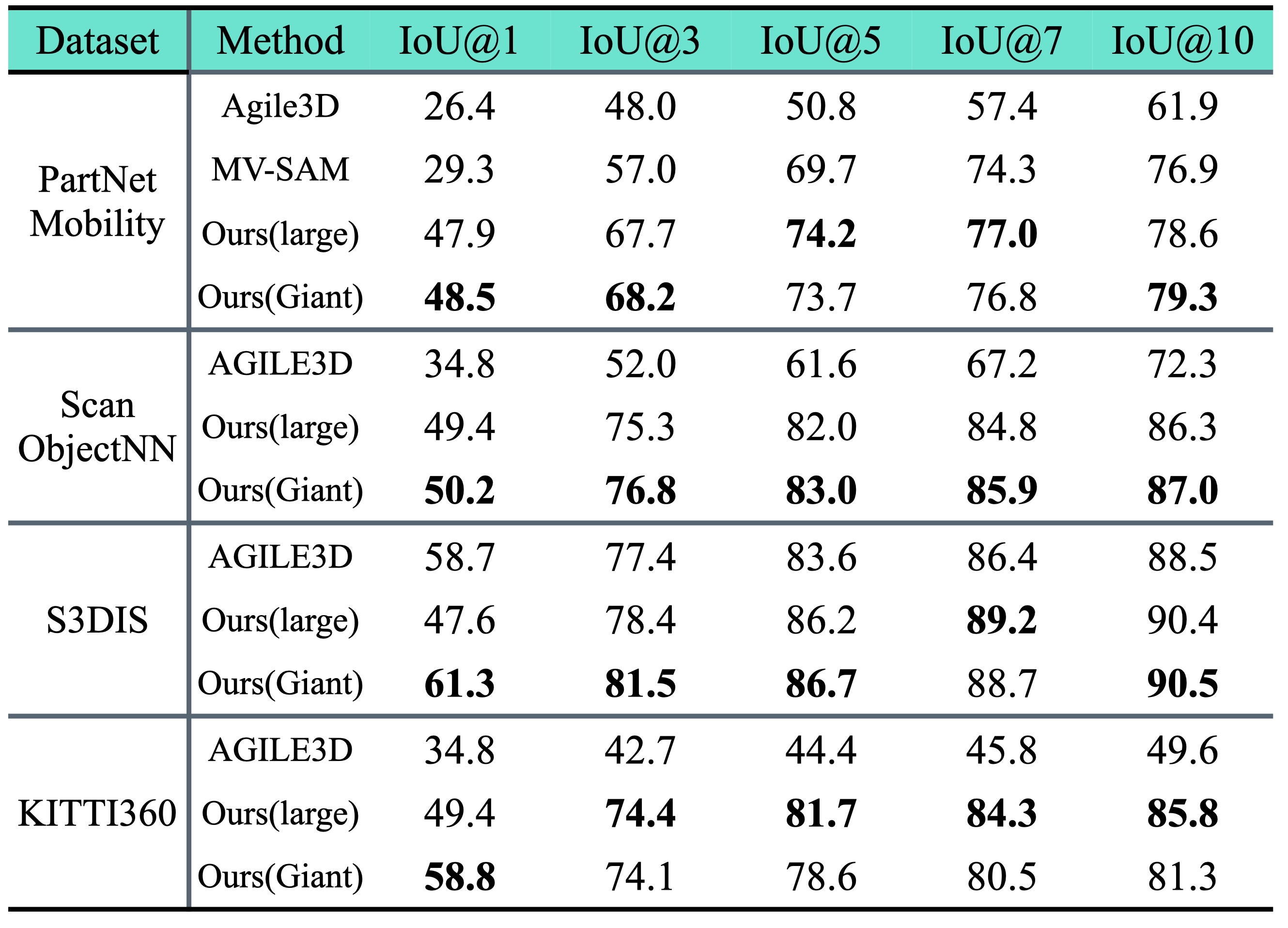
Introduction: Due to advancements in robotics and graphics, there is a growing demand for 3D data with detailed part-level annotations. However, manual annotation of 3D point clouds and meshes is exceedingly laborious and time-consuming. To address this challenge, we introduce Point-SAM, a transformer-based 3D segmentation model designed to incorporate interactive guidance through point prompts. Point-SAM takes both a point cloud and user-provided prompts as inputs, generating precise segmentation masks as outputs. The following videos demonstrate how Point-SAM operates on out-of-distribution meshes.